
為什麼 Google 不適合搜尋判決書?判決搜尋引擎其實這樣設計
作為法律實務者,您是否常為判決搜尋感到困擾?單靠關鍵字與 Google 搜尋,結果往往零散不完整。本篇文章將帶您了解如何結合網路爬蟲與資料結構化,打造一個優質的判決搜尋引擎!

作為法律實務者,您是否常為判決搜尋感到困擾?單靠關鍵字與 Google 搜尋,結果往往零散不完整。本篇文章將帶您了解如何結合網路爬蟲與資料結構化,打造一個優質的判決搜尋引擎!
一、判決搜尋引擎是什麼?與 Google 搜尋有什麼根本差別
(一)搜尋引擎的基本概念:從 Google 搜尋說起
多數法律實務者在進行判決書查詢時,第一個想到的工具往往是 Google 搜尋。然而,Google 搜尋的本質,是在「尋找網頁」,而不是在「理解法律內容」。
Google 的核心任務,是在龐大的網路世界中,快速找出可能與關鍵字相關的頁面。至於頁面裡的內容是否是完整的判決書、是否具備法律效力、是否適用於特定爭點,並不在 Google 搜尋的設計重點之中。
但法律人真正想找的,並不是「包含某些文字的頁面」,而是能夠實際使用的法律資料,例如:特定法院的裁判見解、某一法律爭點的實務判例、具有參考價值的簡易判決等。
這正是判決搜尋引擎存在的原因。
(二)為什麼判決搜尋不能只靠 Google
在法律搜尋的情境中,即使使用完全相同的關鍵字,不同案件的法律效果與立場可能截然不同。
例如,同樣是「不當得利」、「顯失公平」或「侵權行為」,在不同法院、不同案由、不同事實基礎下,搜尋出的判決結果往往差異極大。
此外,法律作為有著高度專業用語的領域,判決書中所使用的用詞往往與一般白話用詞不同,更增添搜尋的難度;更遑論各種法律專有詞、實務慣用語、條文用語彼此交錯,種種特性,皆使得單純依賴 Google 等搜尋網站很難精準完成判決查詢。
(三)與一般搜尋引擎的差異
判決搜尋引擎與一般搜尋引擎最大的不同,在於它處理的是結構化法律資料。
一份判決並不只是「一整篇文字」,其中更包含了多個對法律人至關重要的欄位,例如:
- 法院
- 裁判日期
- 案號
- 案由
- 適用法條
- 主文與理由
並且,法律語言本身具有高度專業性與制度背景,搜尋引擎若無法理解這些結構與語言特性,就難以提供真正有價值的法律搜尋結果。

二、搜尋引擎如何運作?判決搜尋引擎的基本流程拆解
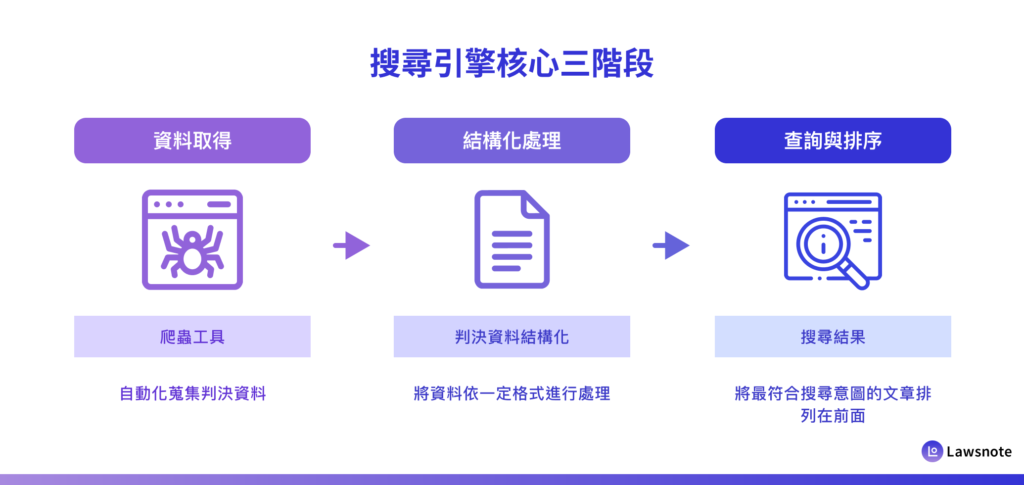
搜尋引擎的三個核心階段
無論是 Google 搜尋,還是專業的判決搜尋引擎,其核心運作流程大致可分為三個階段:
- 資料取得
- 結構化處理
- 查詢與排序
打造判決搜尋引擎的關鍵,就在於如何針對法律資料妥善完成這三個階段。
(一)資料取得
1. 判決搜尋為什麼需要爬蟲?從蒐集到建立資料庫的關鍵
所謂的「爬蟲」,可以理解為一個自動化的資料蒐集助理。它的工作並不是分析法律,而是依照既定規則,持續、穩定地從網路來源蒐集資料。
與人工手動下載判決相比,爬蟲的優勢在於:
- 可長期、自動化更新
- 能系統性蒐集大量判決
- 可避免人工遺漏或重複下載
對於需要建置判決搜尋系統的法律資料庫而言,網路爬蟲幾乎是不可或缺的基礎技術。
2. 判決書查詢資料從哪裡來?
在開始搜集判決書之前,我們需要先知道,判決書屬政府機關公文,原則上並不受著作權保護,但其彙編、整理或加值內容,仍可能另受著作權法保護。
目前判決搜尋引擎的資料來源,主要可分為官方公開來源(如法院公開之判決書查詢系統)及非官方整理平台(如收費商業資料庫)兩類。兩者的差異在於官方公開來源以提供原始判決全文為主,權威但缺乏結構化整理;非官方整理平台則以提供結構化後的判決資料為主,但在使用前必須先確認其所做整理、改編是否受著作權法保護,以及該平台的商業用途規範。
另外,需要特別注意的是,「資料可取得」並不等於「資料可直接使用」;正如廚師有了菜(原始素材),還需要經過處理、烹飪才能成為一道完整的菜餚(可使用的內容)。
究其原因,在於儘管判決書已公開,其格式、完整性與一致性,仍可能存在相當大的差異。這些不一致可能來自不同法院、不同審級所使用的不同寫作習慣;或因年份、案由、裁判類型不同而有標示方式的不同。
因此,爬蟲取得的原始資料,往往只是「素材」,而非可以直接用於判決搜尋引擎的成品。這也是我們下一步要做的:資料結構化處理。
(二)結構化處理
1. 什麼叫「結構化一份判決」
所謂結構化,是指將一份資料,依據一定的格式拆解成系統能夠有效搜尋與理解的欄位,例如一份判決可以被分為:
- 法院
- 案由
- 裁判類型
- 適用法條
- 主文
- 理由
這似乎看起來非常自然,為什麼需要特意進行結構化操作?這是因為儘管人類可以理解頁面內容,自己辨識「哪一段落是案由」、「哪一部分是涵攝」,然而對於系統而言,這些都僅是「純粹的文字」而無法完全掌握其意涵。
因此透過結構化處理,我們可以將判決從大段文字轉為能被系統精準檢索的法律資料,更加貼合法律人的需求。

2. 缺乏結構化時,判例查詢會遇到哪些限制
過去當我們只依賴全文搜尋時,判決查詢往往會出現以下問題:
- 找到大量不相關結果
- 關鍵字出現,但並非核心法律爭點
- 無法有效比較不同判決的實務見解
而結構化資料則能讓搜尋引擎理解「這段文字是在主文」、「那段文字是理由」,從而大幅提升法律搜尋的精準度與可用性。
(三)查詢與排序
對使用者而言,搜尋的目的並非「看到最多結果」,而是「快速找到最相關、最有用的內容」。因此,搜尋引擎的查詢設計與排序邏輯,將直接影響搜尋體驗的好壞。
1. 好的查詢設計如何反應使用者的需求
現代搜尋引擎的核心,已從單純比對關鍵字,轉向理解使用者輸入的「查詢意圖」。透過關鍵字同義詞處理與相關概念辨識,搜尋引擎不再只檢查文字是否完全一致,而是判斷不同表述背後是否指向相同實質意義。這在判決搜尋中特別重要,因為同一法律概念常有多種寫法,但法律效果與實務意義高度相似(例如:凶宅/兇宅、新法名稱對應舊法)。
結合資料結構化後,搜尋引擎還能將查詢限縮於特定段落或欄位,進一步提升精準度。
以 Lawsnote Search 為例,使用者可以透過語法,針對特定結構欄位進行搜尋:
- 主文搜尋:
使用 main: 來搜尋主文,多個關鍵字需分別使用多個 main: - 特定身份搜尋:
使用語法 法官:來搜尋特定法官
這類結構化搜尋方式,能協助法律人更快找到真正有用的判決資料,不被大量無關結果淹沒。
2. 排序如何提升判決查詢效率與準確度
在完成有效的查詢設計後,排序機制則決定搜尋結果是否「好用」。
傳統搜尋引擎多依時間新舊或標題是否包含關鍵字進行排序,當資料量擴大時,這種方式便難以反映結果與需求之間的真實關聯。
現代判決搜尋引擎則以關聯度排序為核心,綜合考量內容與核心關鍵字、法律概念之間的關係,將最符合使用者需求的結果優先呈現。透過這種排序方式,真正相關的判決能被推到前面,不再被時間或表面文字干擾,從而大幅提升判決查詢的效率與準確度。

三、判決搜尋工具怎麼選?同時兼備完整性和精準性
當市面上有不同的判決搜尋系統時,要怎麼評估選擇哪一家的判決搜尋系統呢?對於法律工作者來說,應該先考慮搜尋的完整性,也就是各種符合條件的判決是不是能被完整地呈現在搜尋結果,甚至各種法律上的同義字也可以一併搜尋出來。
其次,要考慮判決搜尋的精準性。對於法律工作者來說,時間是非常寶貴的資源,如何能用最有效率的方式找到自己需要的判決,是評估一個判決查詢系統重要的要素。即使關鍵字搜尋策略相同,但不同判決查詢系統所提供的排序方式和資料結構化的支援,將大幅影響法律人的工作效率,因此越好的判決查詢系統,往往意味著可以讓法律工作者大幅節省更多判決搜尋所花費的時間。
四、判決資料太多不知從哪下手?Lawsnote Search 讓查詢更精準
判決搜尋引擎的真正價值,不在於技術本身,而在於是否貼近法律實務的使用情境。
當搜尋引擎能理解法律語言、結構與實務需求時,法律人才能把時間花在分析與判斷,而不是反覆嘗試搜尋關鍵字。查判決最怕花時間又找不到重點,Lawsnote Search 讓你更快定位到關鍵判例與段落:
- 更完整:Lawsnote 判決查詢提供多種法律同義字搜尋,讓您查詢「僱傭」同時也可以搜尋到「雇庸」
- 更精準:透過結構化篩選和關聯度排序,用法院、案由、裁判類型、裁判日期、引用法條等條件快速縮小範圍,並提供法律工作者專用的排序演算法,讓您更快的找到所需要的資料。
👉 立即使用 Lawsnote Search,別再靠關鍵字碰運氣!