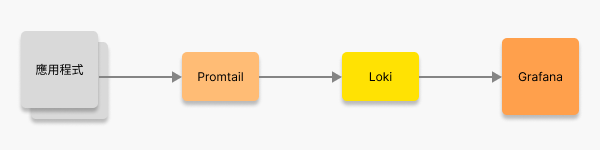
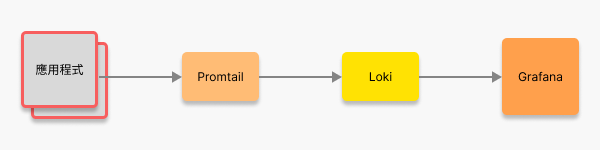
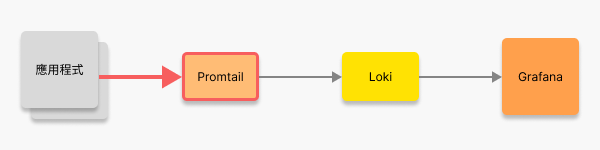
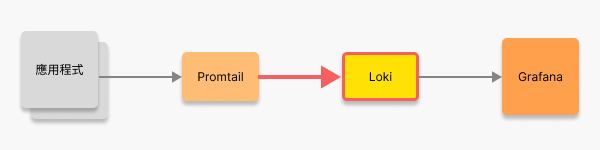
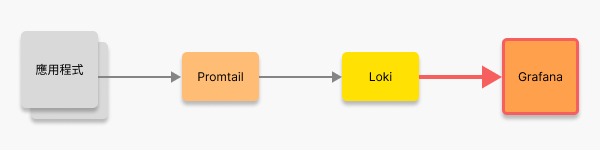
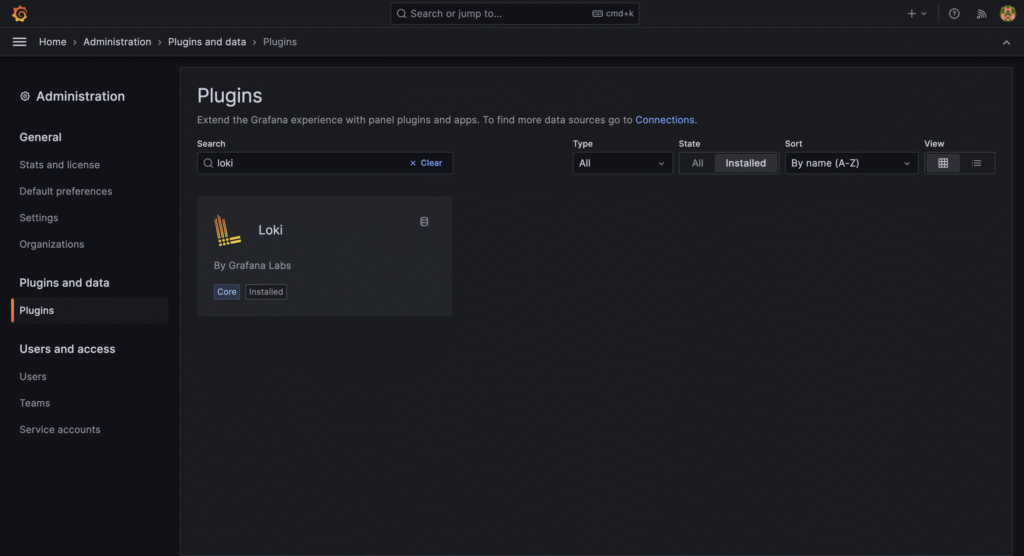
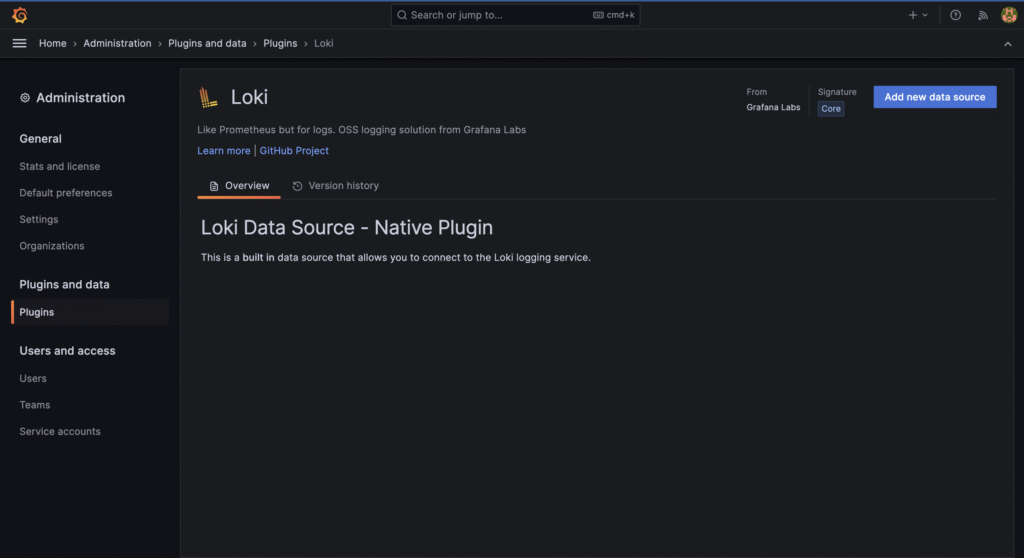
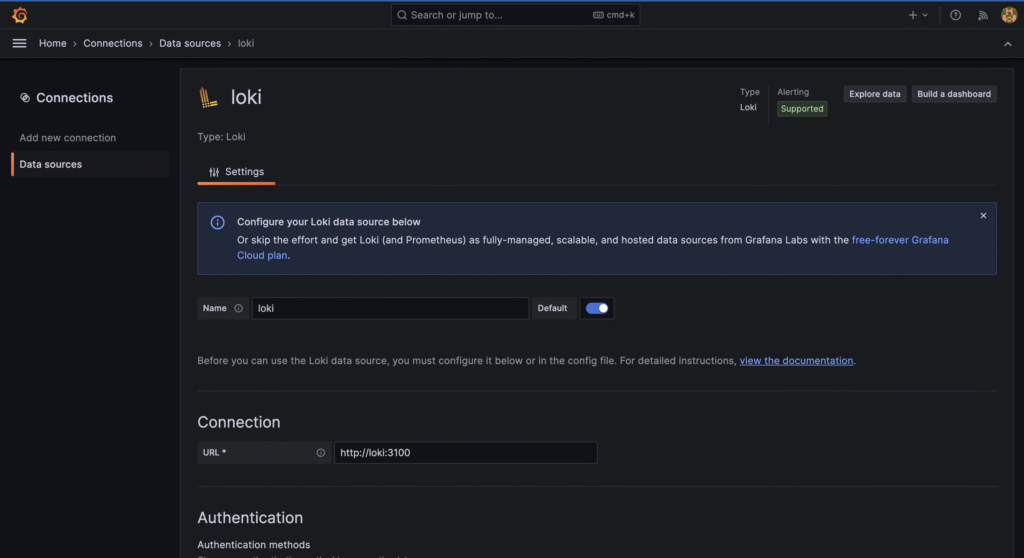
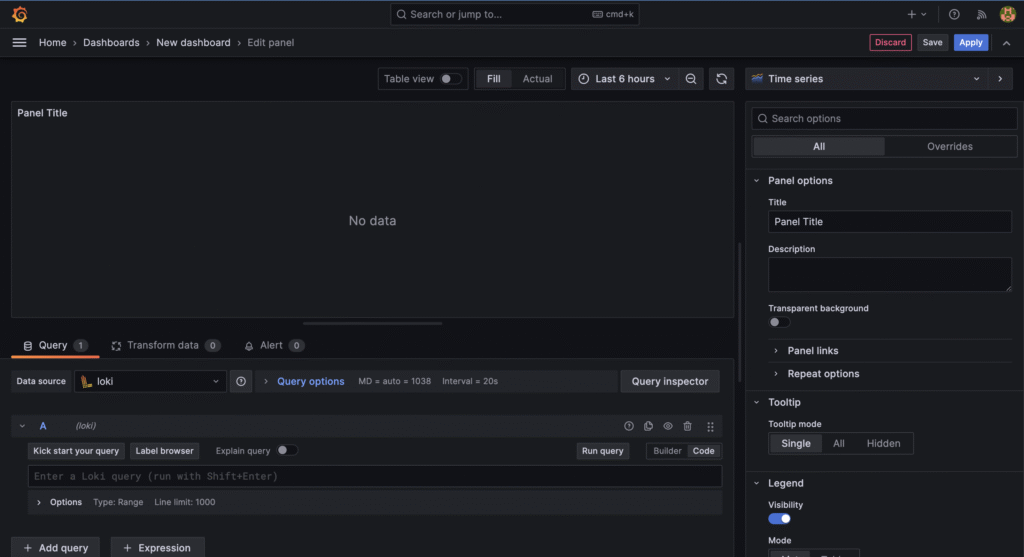
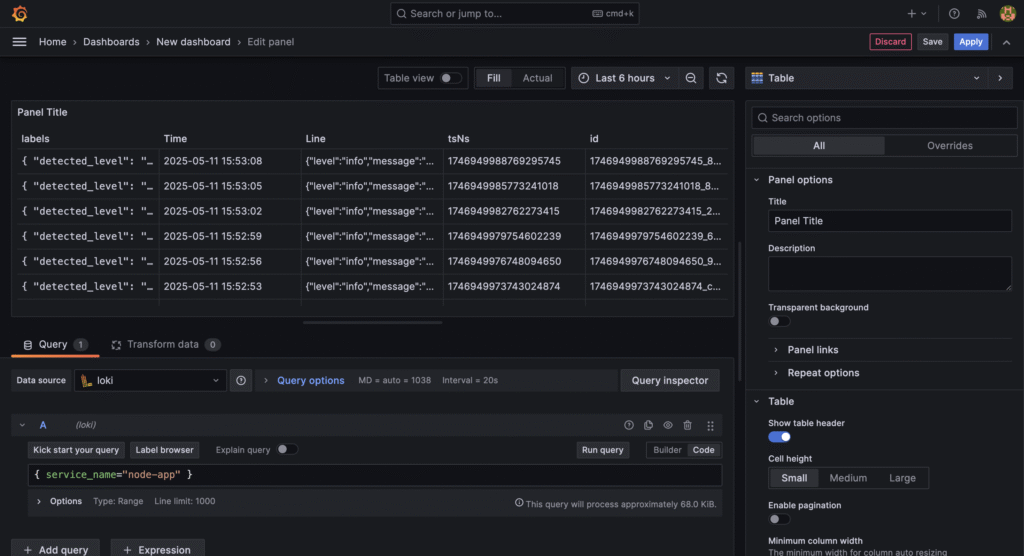
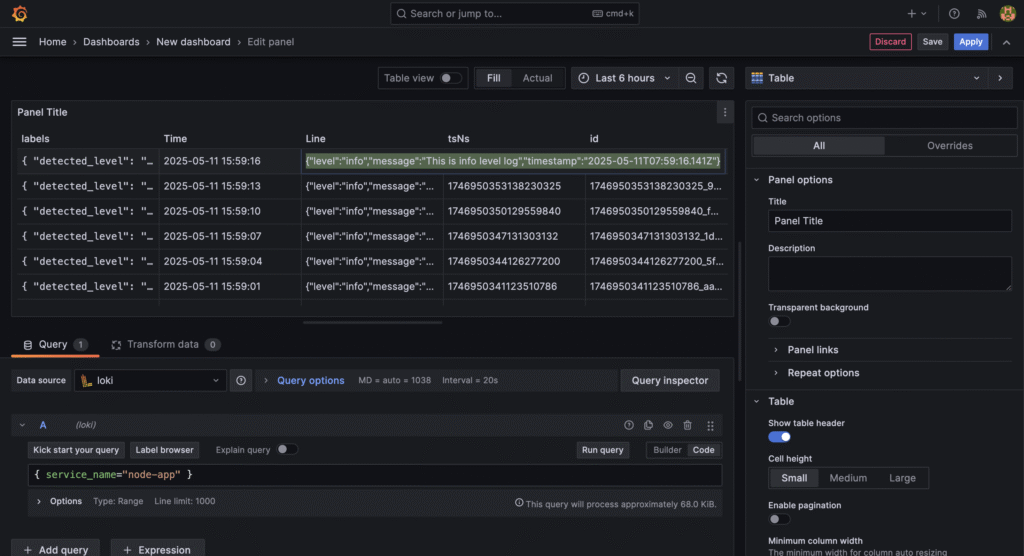
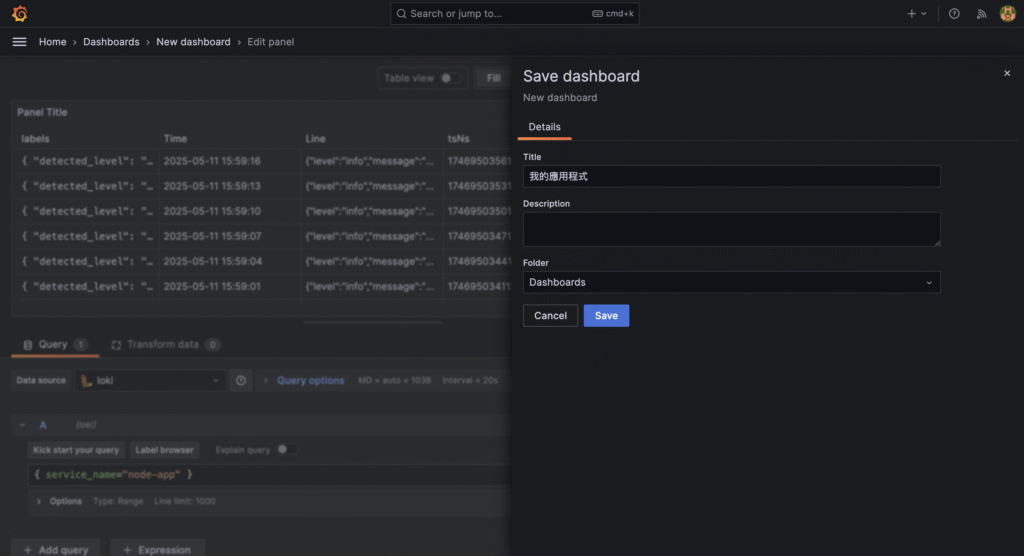
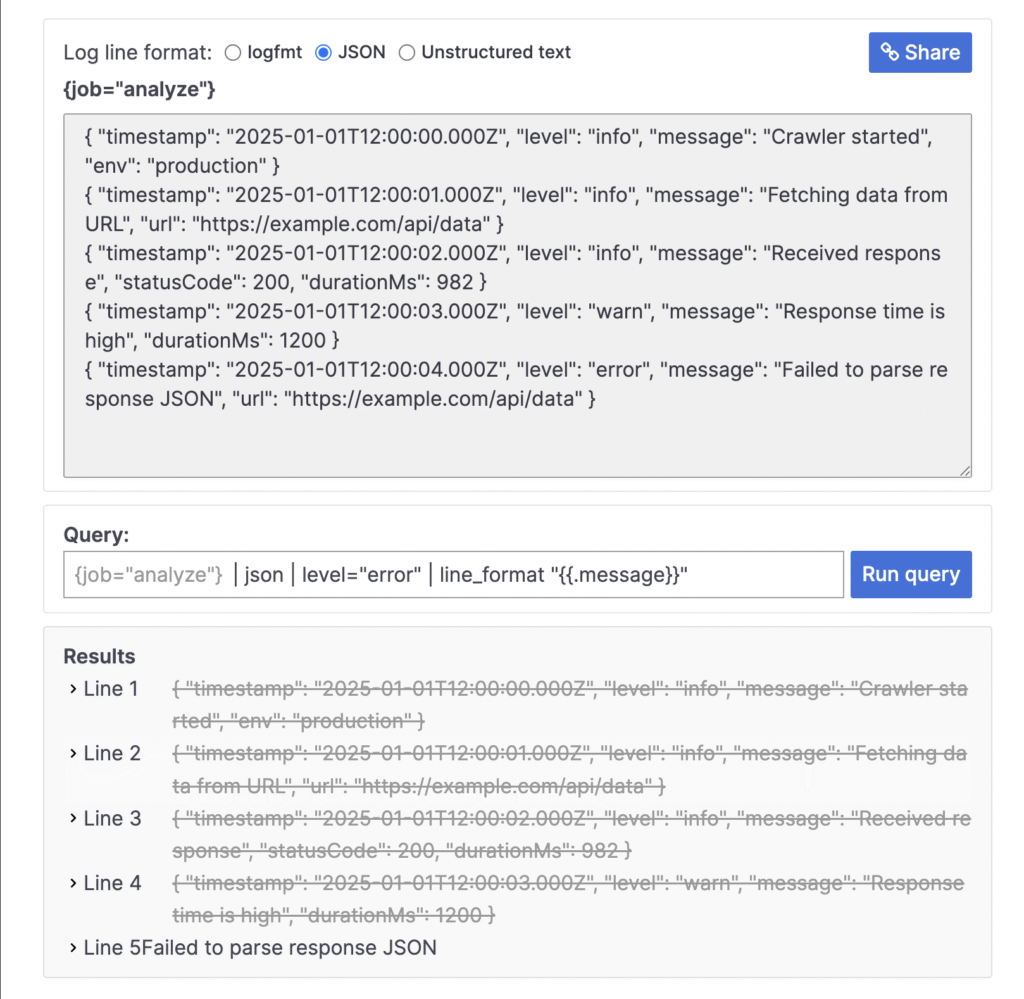
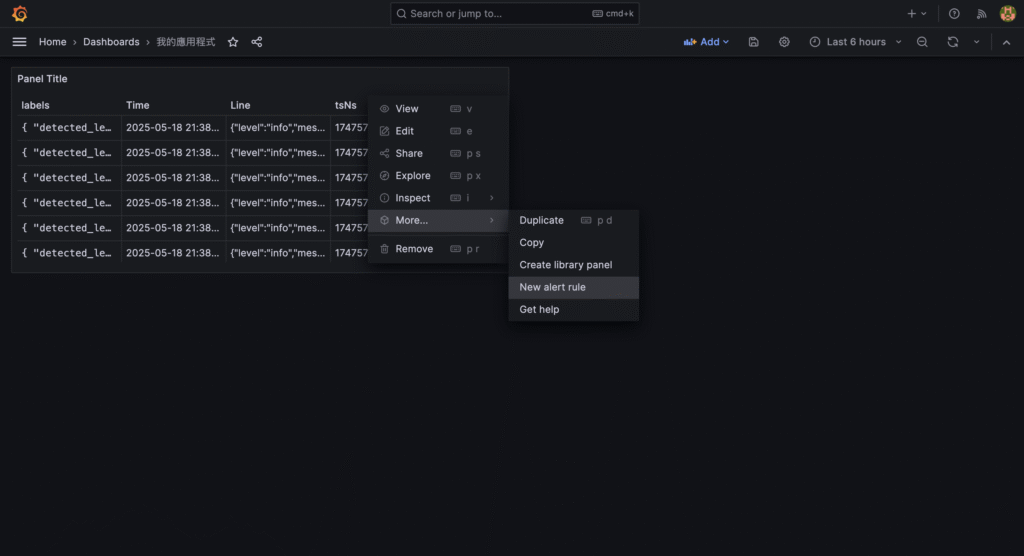
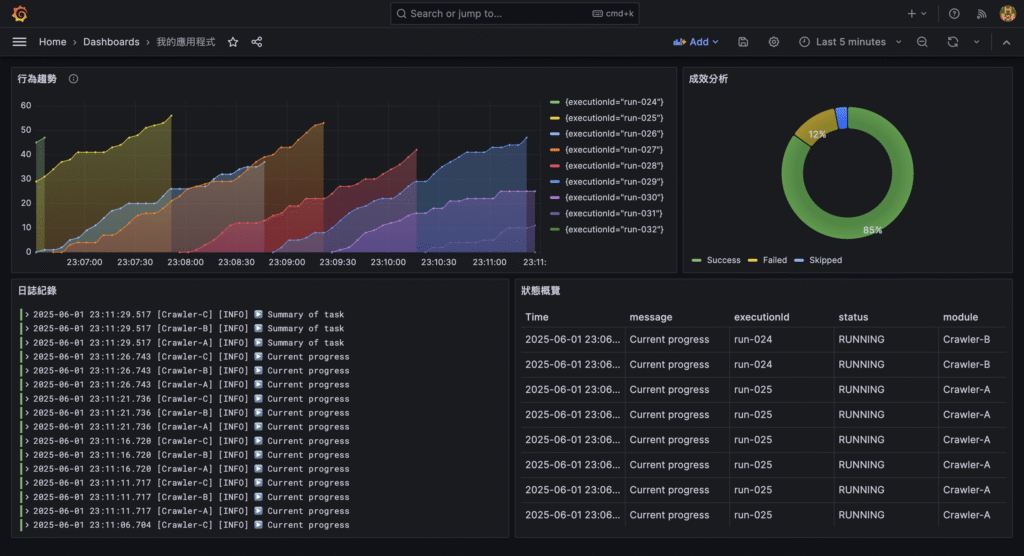
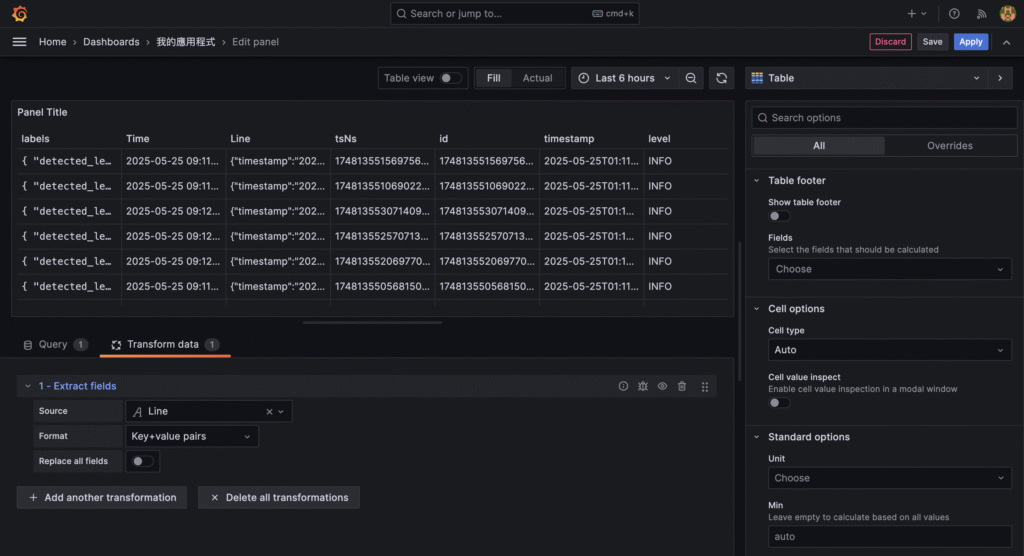
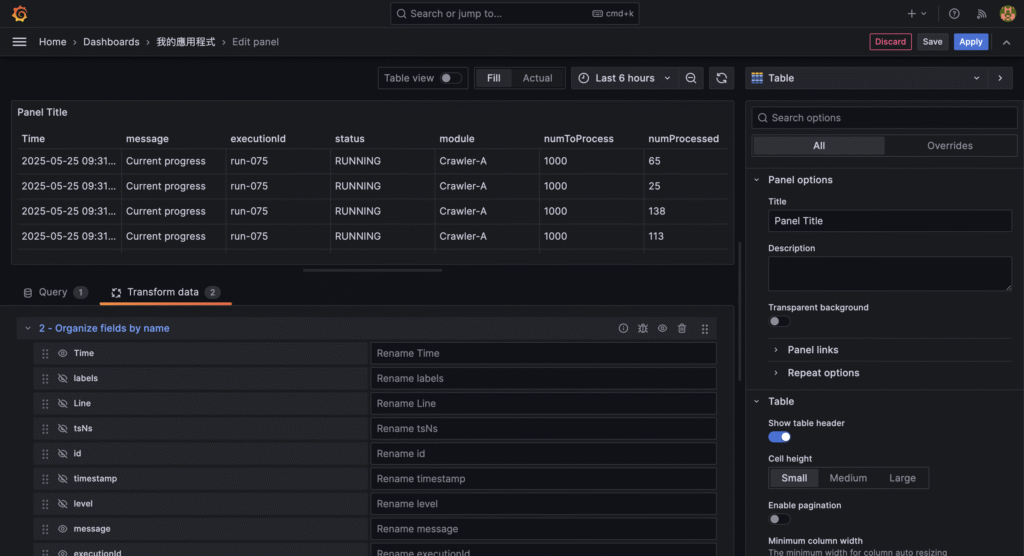
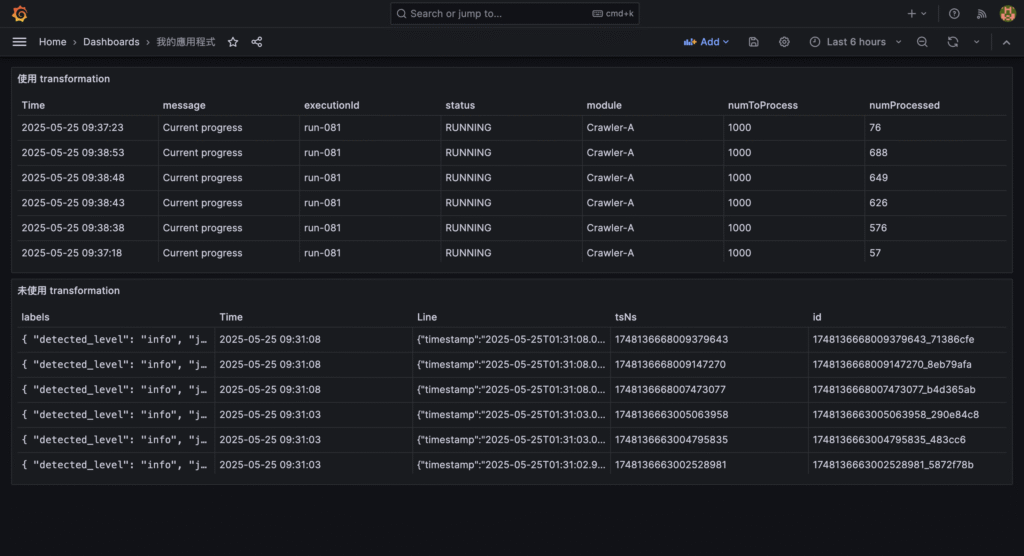
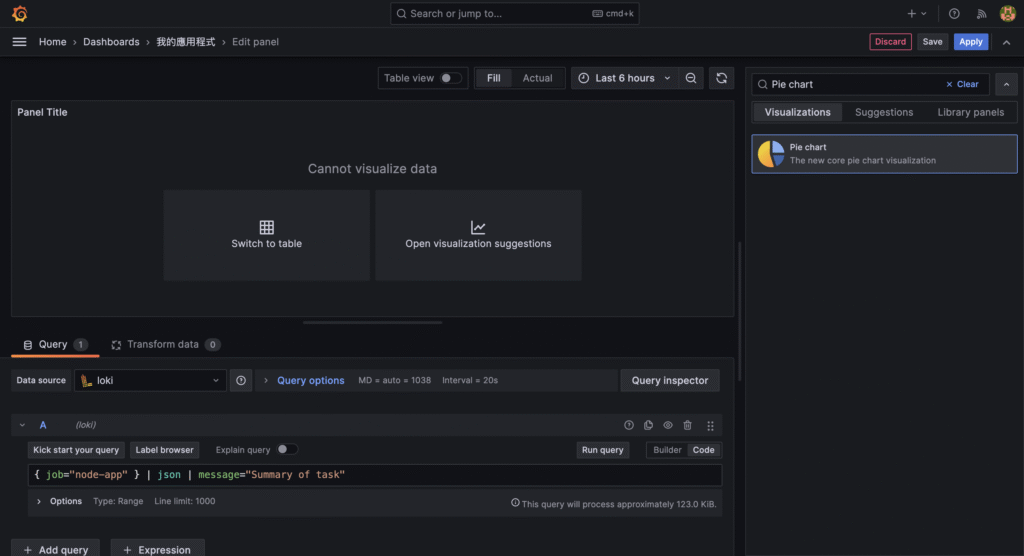
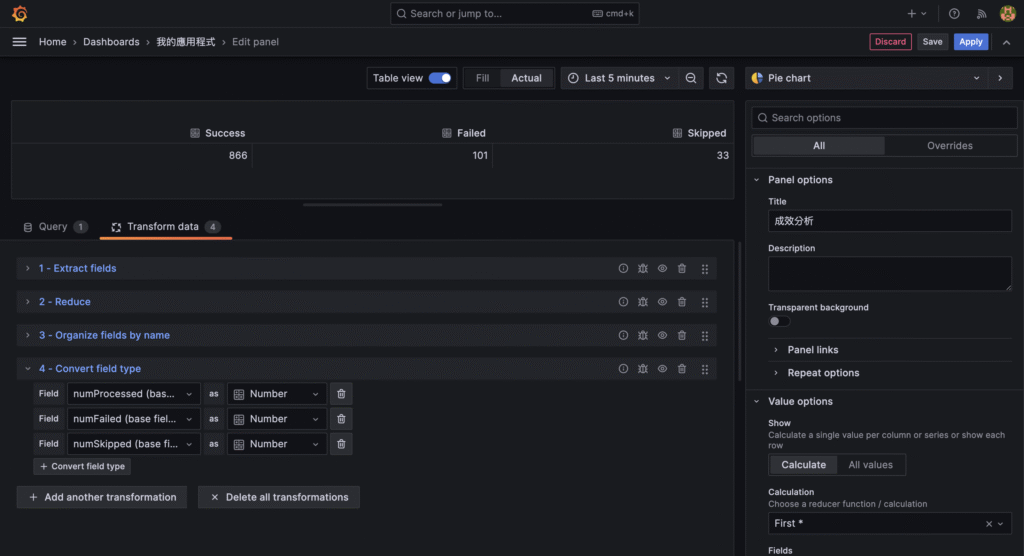
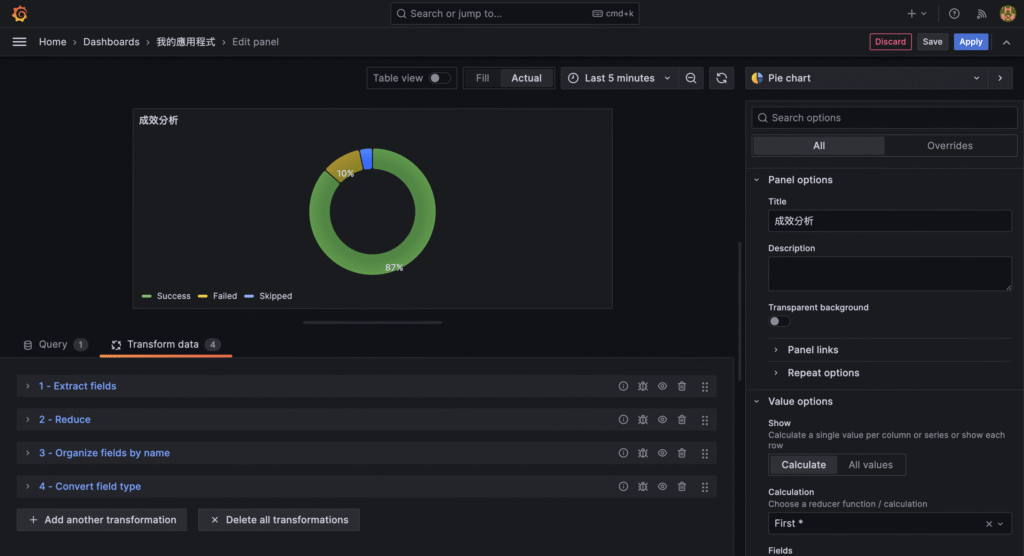
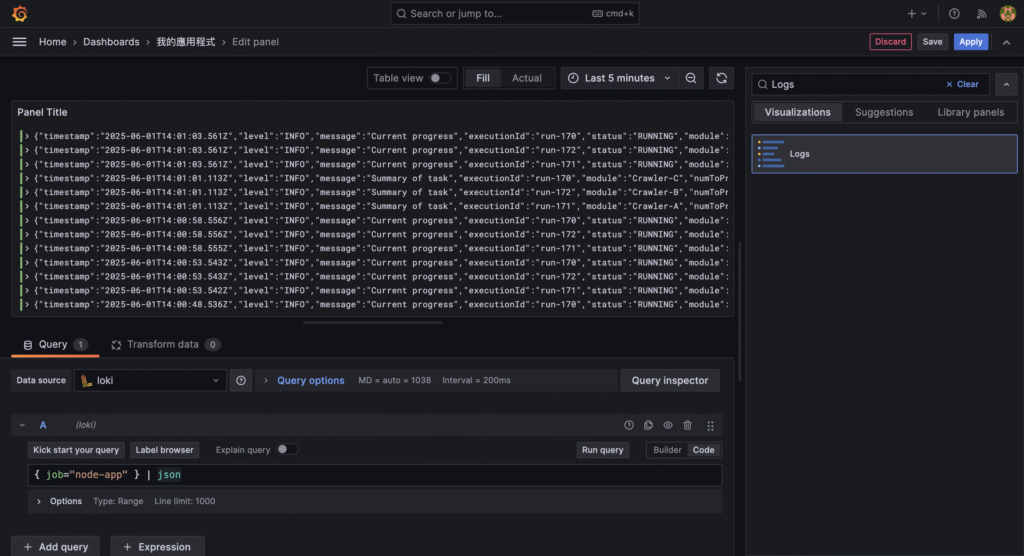
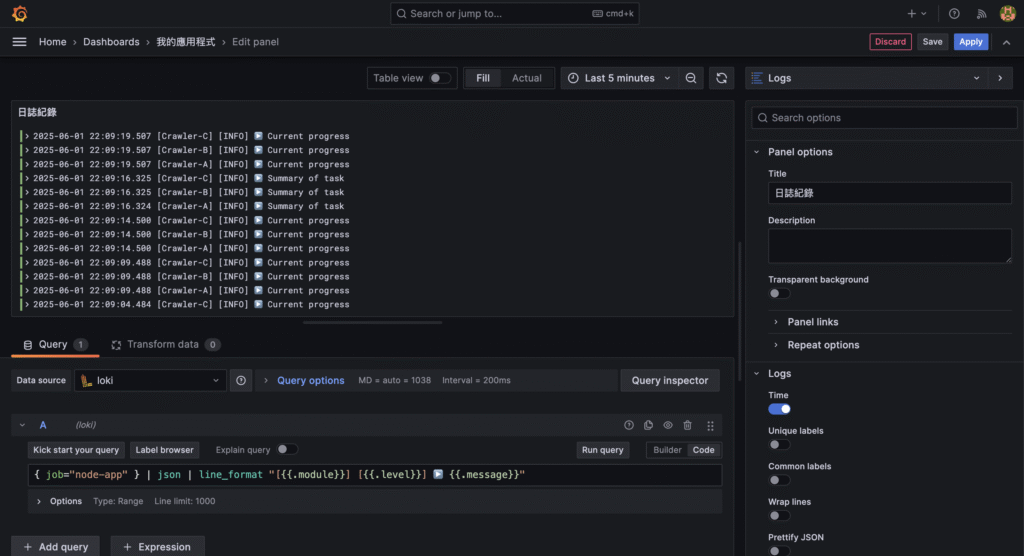
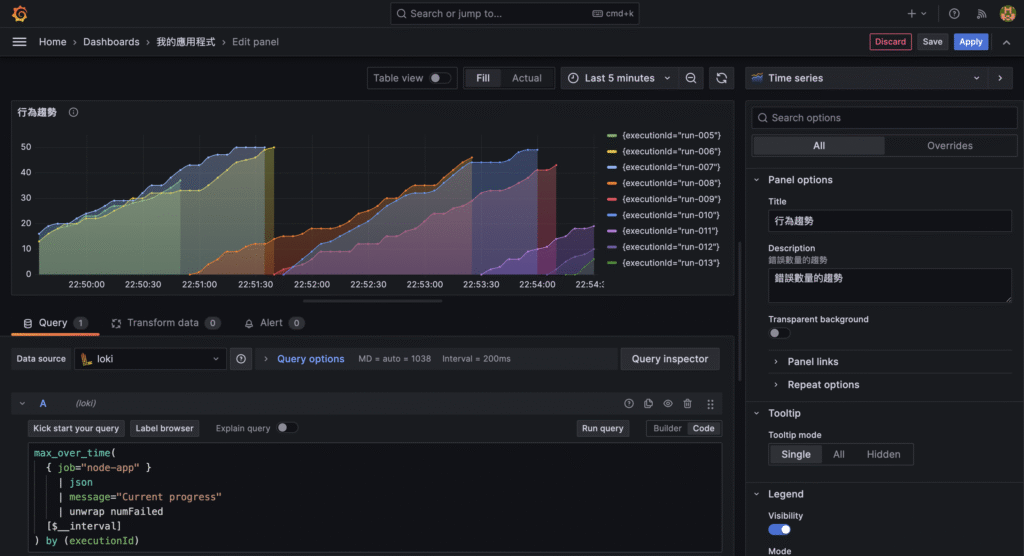
{ "timestamp": "2025-01-01T12:00:00.000Z", "level": "info", "message": "Crawler started", "env": "production" }
{ "timestamp": "2025-01-01T12:00:01.000Z", "level": "info", "message": "Fetching data from URL", "url": "https://example.com/api/data" }
{ "timestamp": "2025-01-01T12:00:02.000Z", "level": "info", "message": "Received response", "statusCode": 200, "durationMs": 982 }
{ "timestamp": "2025-01-01T12:00:03.000Z", "level": "warn", "message": "Response time is high", "durationMs": 1200 }
{ "timestamp": "2025-01-01T12:00:04.000Z", "level": "error", "message": "Failed to parse response JSON", "url": "https://example.com/api/data" }