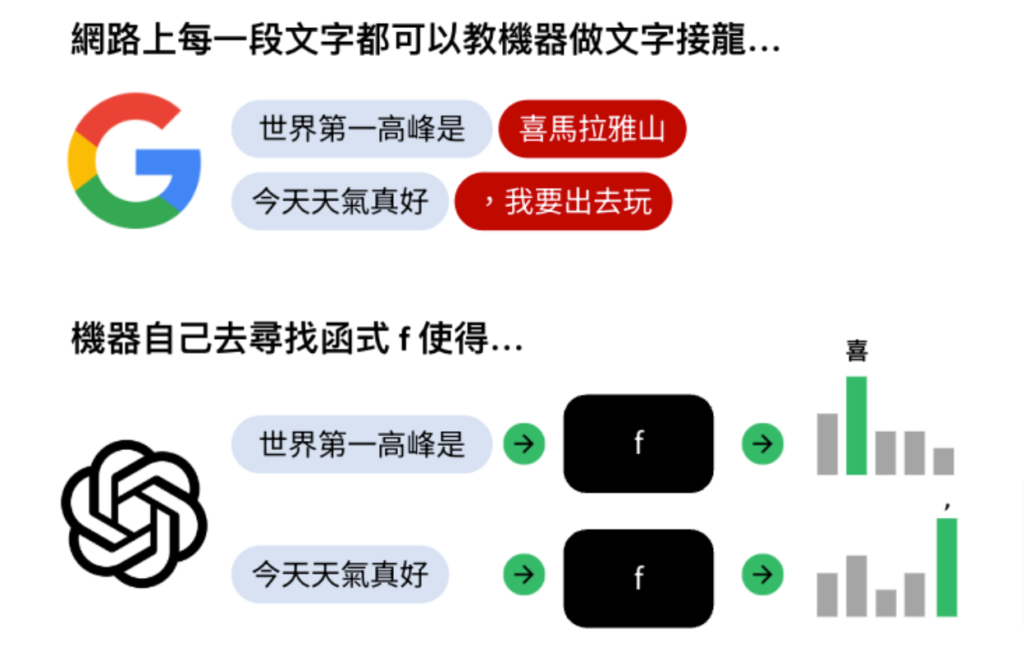
生成式 AI 泛指利用提示詞(prompt)來生成內容的人工智慧應用,核心技術是大型語言模型(Large Language Model, LLM),雖然大型語言模型主要是指處理「文字」的模型,但生成式 AI 同時也包含了影音圖片等內容的生成。
我們可以用汽車的類比來理解這些名詞:
大語言模型 LLM:核心模型,例如引擎
OpenAI:公司名稱,例如 Toyota
ChatGPT:服務名稱,例如 Yaris 車款
GPT4o:模型型號,例如 Yaris 車款引擎型號 2NR-FE
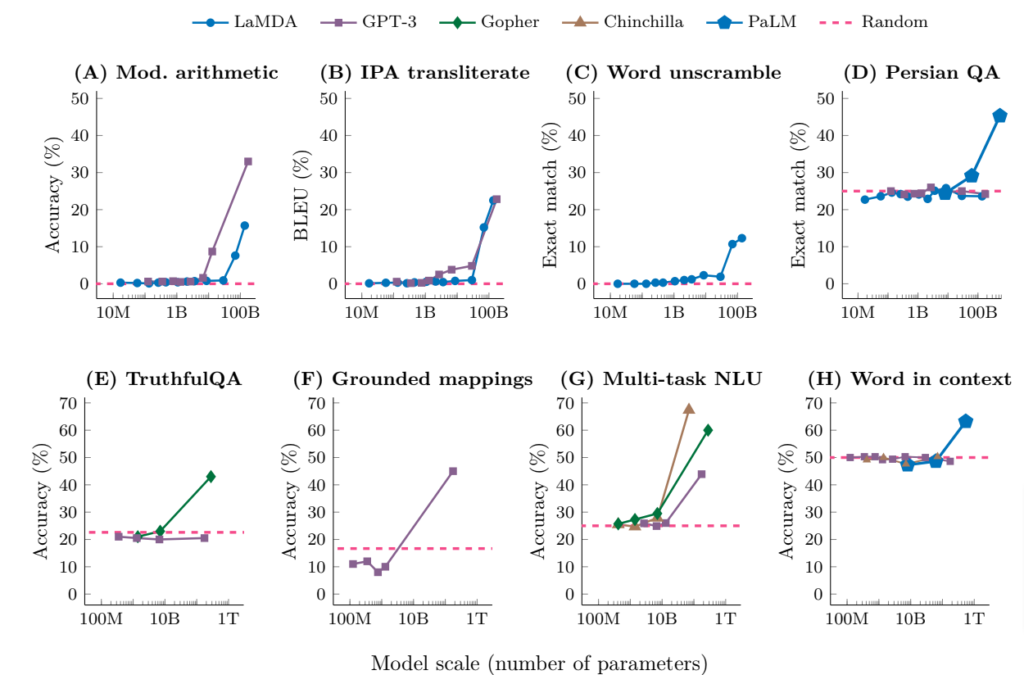
至於應用大語言模型的生成式 AI,跟之前的 AI 有什麼差別,最重要的區別在於訓練資料和參數的量級持續增加,讓量變產生質變,讓模型發生了「智慧湧現」(emergent ability)的現象,也就模型突然變聰明。這個現象並不是慢慢發生的,而是在模型的參數與訓練量級超過某一個數值的時候,突然發生,下圖就是各個模型的智慧湧現現象:
引用論文:Emergent Abilities of Large Language Models(Jason Wei, et al., arXiv, 2022.)
第二種情況由於使用者無法確認 LLM 是否為幻想,因此不宜使用 LLM,即使在第一種情況,也需要實際確認 LLM 產出的正確性,美國和加拿大都曾發生過律師在法庭上提出了 ChatGPT 憑空杜撰的判決書的案例,源自於誤把生成式 AI 當成搜尋引擎來使用,但兩者其實是完全不同的服務。
以目前法律服務業界而言,生成式 AI 主要應用場景包含翻譯、製作會議記錄摘要、潤飾文字修辭、產生文件初稿和大綱、摘要大量文本重點、圖檔(或 PDF)轉文字檔等應用。
然而,生成式 AI 會幻想的問題,並不是無法克服的。透過掛載搜尋引擎的生成式 AI,可以有效降低 LLM 的幻想問題,在業界稱為 RAG(Retrieval-Augmented Generation, 擷取增強生成)。
我們會在後面的文章談到如何透過 RAG架構,讓生成式 AI 來回答法律問題。
3. 法律工作具有機密性,不能使用生成式 AI?
在使用生成式 AI 的時候,你所有輸入的資料,包含輸入的文字和上傳的檔案都可能面臨至少兩個階段的外洩風險:
這些資料很可能會先存放在服務提供者的伺服器中,這些伺服器雖然通常不會讓一般人存取,但根據 OpenAI 的 FAQ,使用者在 ChatGPT 輸入的資料除了 OpenAI 的人員可以存取外,它們也會提供給一組「可以信任的服務提供者」(a select group of trusted service providers),但沒有說明具體是誰。
至於如何避免資料外洩,除了在輸入資料的時候先「去機密性」之外,也可以考慮使用封閉型的 LLM:將生成式 AI 服務部署在自己私有的伺服器中。
這樣的模式有兩種選擇:
將開源的大語言模型放在自己的伺服器中:這樣的方式可以確保所有的資料都不會流到第三方的手中,而且無須負擔 token 的費用(token 的計費方式可參考這篇文章),但對於硬體效能和技術開發的要求比較高,並且僅能使用開源的大語言模型。目前包含 ChatGPT 和 Claude 都屬於閉源模型,無法直接部屬在自己的環境中,台灣目前主流的開源模型以 Meta 開發的 Llama3 和 Mistral AI 開發的Mixtral為主,兩者都有團隊進行繁體中文的優化。
因此,若非有全新架構的 AI 出現,讓人工智慧發展出邏輯推理等能力,否則我們的見解至今仍然沒有改變,生成式 AI 不會取代律師。
但作為工具,生成式 AI 絕對是未來律師必須熟練使用的工具。工具雖然無法取代律師這個角色,但熟練使用生成式 AI 的律師,會比不使用生成式 AI 的律師來的更有競爭力。
8. 在 AI 時代,文組會更沒有價值?
生成式 AI 的發展可能造成專業壁壘趨向模糊。大型語言模型透過提示詞生成文件、翻譯資料和摘要文本,這些過去需要專業技能的任務,透過LLM變得更高效。生成式 AI 的應用使專業與非專業的界線沒那麼明顯,許多專業工作變得更容易執行。
工業時代強調專業分工以最大化效率,每個人專注於特定任務,形成高度專業化的結構。然而,生成式 AI 能快速學習和模仿專業知識,在某些領域甚至超越人類,因此,專業技能不再是高效工作的唯一保證。
在 AI 時代,解決問題的方法論變得重要。僅有專業知識已不足夠,取而代之的是如何有效解決問題的能力。例如,律師需要不僅是法律知識,還需懂得如何解構工作流程,轉化為步驟和提示詞,利用生成式 AI 提升工作效率,解決客戶問題。這種方法論的重視,使解決問題能力在 AI 時代更具競爭力。
隨著生成式 AI 普及,「規劃、策略和決策」的價值提高,執行的價值下降。自動化的重複性和標準化任務減少了對人力的需求。因此,決策者和策略規劃者的角色變得更重要,他們需制定合理的策略和步驟,確保 AI 工具有效服務客戶需求。在 AI 時代,真正有價值的是規劃和決策工作,而非那些可被 AI 取代的執行工作。
因此,AI 時代並未讓文組的價值消失,而是發生了轉變。專業壁壘變模糊,但專業知識需與解決問題的方法論結合,才能發揮更大價值。規劃、策略和決策的重要性超越執行,成為 AI 時代不可或缺的核心能力。文組在 AI 時代的角色轉變,是價值的再定義,而非減少。