
Lawsnote 觀察報告(2019)
本報告由 Lawsnote 的觀察為核心,整理目前人工智慧技術在台灣法律領域的發展狀況作為參考資訊。
- 人工智慧:本篇報告將人工智慧的概念限縮到至少使用了機器學習的技術。
- 觀察範圍:以可取得的公開資訊為基準,觀察產業、學界、官方以及社群活動的發展現況:
- 學界以法律相關及資訊工程為重點
- 產業界以法律科技新創為重點
- 官方以司法院和法務部為重點
- 社群活動著重於g0v大松、法律科技黑客松以及總統盃黑客松
主要應用場景與進度
- 預測模型
預測模型指的是透過分析過往的公開資料(主要著重在於裁判書),建立一個預測案件結果的機制,是人工智慧在法律領域應用最多的形式,包含:
- 判決結果的預測:勝率多少?是否成罪等等的預測
- 刑度的預測:法官通常判處刑度的預測
- 金額的預測:慰撫金、精神損害等抽象損害的金額預測
- 部分認定結果的預測:凶宅認定、由父或母行使親權的可能性等等的預測
- 歸責比例的預測:兩造各負擔多少比例責任的預測
預測模型為官方和學界主要使用人工智慧的場景,幾乎所有的預測模型都限定在特定領域,例如婚姻事件、車禍或酒駕等等,極少見泛用領域的預測模型。
在預測準確率上,由於目前預測系統缺乏標準化的精確度驗證方法與驗證資料庫,因此多以研究者自行公開的準確度為主,目前也沒有觀察到以再現性實驗的研究,因此關於現行準確率的進度較難驗證。
目前觀察到準確度最高者為親權歸屬預測模組,準確率在 98% 以上(黃詩純、邵軒磊 ,運用機器學習預測法院裁判──法資訊學之實踐 2017)。
建模訓練資料的數量級區間,受限於人工標記的成本和專案規模,大多在 1,000 筆以下,少數有使用自動標記的技術,數量可達數千筆,但多數仍在 10,000 筆以下,另外特定領域的案件量不足也常常是建模上可能面臨的一些問題。
成果部分,除了學術論文發表外,有數個預測系統提供線上使用,例如:
- AI 輔助親權判決預測(林昀嫺、王道維,清華大學科技部計畫)。
- 智慧凶宅判斷系統(侯魏珍等,法律科技黑客松)
- 台北市車禍賠償金額分佈(蔡維哲等,法律科技黑客松)
目前觀察到建立預測模型的方法論主要有四種:
- 裁判書斷詞清洗後,不標記直接作為建模訓練素材。
- 裁判書斷詞清洗後,將關鍵詞標記為結果因子,使用因子作為建模訓練素材。
- 預定義結果因子,不斷詞,直接將裁判書萃取出因子後,使用因子作為建模訓練素材。
- 不斷詞也不考慮結果因子,直接標記裁判書的特定描述句(Sentence),將標記好的句子作為建模訓練素材。
- 分類器
分類器是英美法系國家應用最廣泛的一種場景,主要應用在 eDiscovery 的過程,台灣由於沒有 Discovery程序,缺乏主要應用場景,因此較少觀察到分類器的應用。
少數有使用則在裁判案件的分類,例如:「人工智慧於法律的應用 – 死刑與無期徒刑的案件分類,段品任等」和「利用機器學習於中文法律文件之標記與分類,林琬真等」。
另一種則是文本段落的分類,例如 Lawsnote 透過詞向量機率模型完成裁判書的段落分類,將裁判全文分為「原告主張」、「被告主張」、「法院見解」和「判決爭點」等段落,目前已經實現商業化。
- 搜尋
透過人工智慧來實現自然語言搜尋的方法論逐漸成熟,無論是透過詞向量模型來計算多維空間距離,或是透過自動擷取關鍵字來進行模糊搜尋,概念和演算法都已經行之有年,在美國,自然語言搜尋場景主要有兩種模式,其一是透過人為輸入自然語言(例如問一個問題)來完成搜尋,其二是使用文本(例如上傳一份文件、訴狀)來搜尋相關資料。
搜尋本身較難成為學術研究成果,比較著重在產業價值,因此學術上較少研究,並且由於在台灣,法律領域的自然語言搜尋的表現尚未達商用的水準,因此目前都處於產業界實驗階段,目前少見的成果為台灣法律科技黑客松的概念產品:「法律科技黑客松:透過會議紀錄搜尋相關判決,賴郁樺等」。
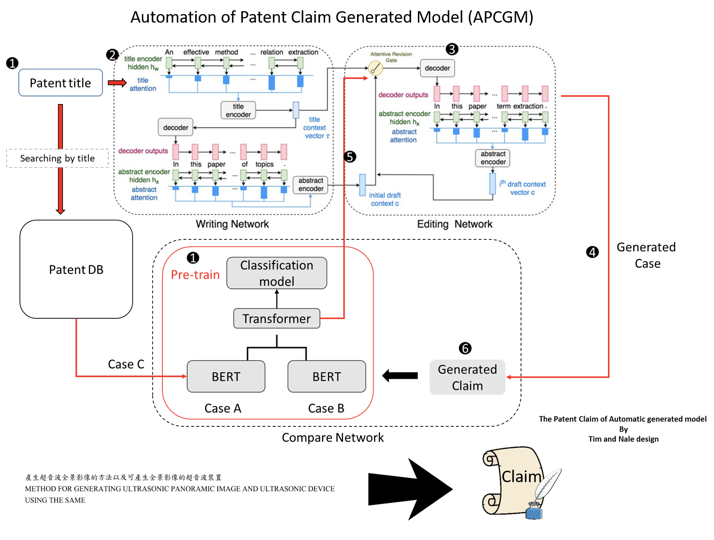
- 自動生成文件/自動完成
在目前線上的法律文件生成服務中,並沒有觀察到使用人工智慧,目前觀察到的所有的法律文件生成服務都是基於 Rule-base。
即使在法律以外的中文文件生成服務,在語意理解的深化還有許多優化的空間,根據我們對其他國家發展的觀察與推測,法律文件生成的成熟發展會稍微置後於較熱門的語意分析領域,例如輿情分析、新聞、客戶支援及行銷文案等。
在概念性專案「法律科技黑客松:專利修修臉,楊岱瑾等」中,利用了 Open-AI NLP Model 和生成對抗網路 (GAN,Generative Adversarial Nets) 來產生優質的專利 Claim(申請權利範圍),是目前少見利用人工智慧生成法律文件的專案。
- 自動結構化和自動標記
目前各種法學資料無一例外地屬於高度非結構化資料,因此在建模或分析前置的資料結構化、清洗與標記則扮演非常重要的角色。目前多數使用人工智慧技術的結構化資料來源為人工標記資料、因此作為訓練素材的資料量級都十分有限,其中,有少數使用了自動結構化的方式來提高數量級。
現行主流的自動結構化仍是仰賴 Rule-base的資料探勘,例如透過 Regular-expression 定義裁判中涉及特定因子的 pattern。
人工智慧在自動結構化和標記上雖然還不成熟,但有少數應用。
有部分研究開始嘗試用機率模型來實現自動結構化。例如「機器學習於中文法律文件之標記與分類,林琬真等」,該篇論文就是先將裁判書文本拆解為關鍵詞的集合,使用手動標記一部分的關鍵詞集合,其餘的關鍵詞集合則透過機率模型進行自動標記,不過根據此篇論文的作者認為自動標記還有很大的優化空間。
此外還有使用根據 OpenIE (Open Information Extraction) 概念的結構化技術,如利用 Standford coreNLP 來將裁判書的主體關係進行結構化,不過這種結構化資料的應用可能比較沒有那麼泛用,主要用在特定應用場景的結構化。
另一種做法是透過無監督式的 Transfer Learning(如Bert)搭配 Question-Answer-Pairs 的半自動學習,可透過問句實現自動結構化,在「法律科技黑客松:犯罪人嫌疑網路,姜力綱等」專案內,此種自動結構化可以用於預先定義好的人、事、時、地等標籤。
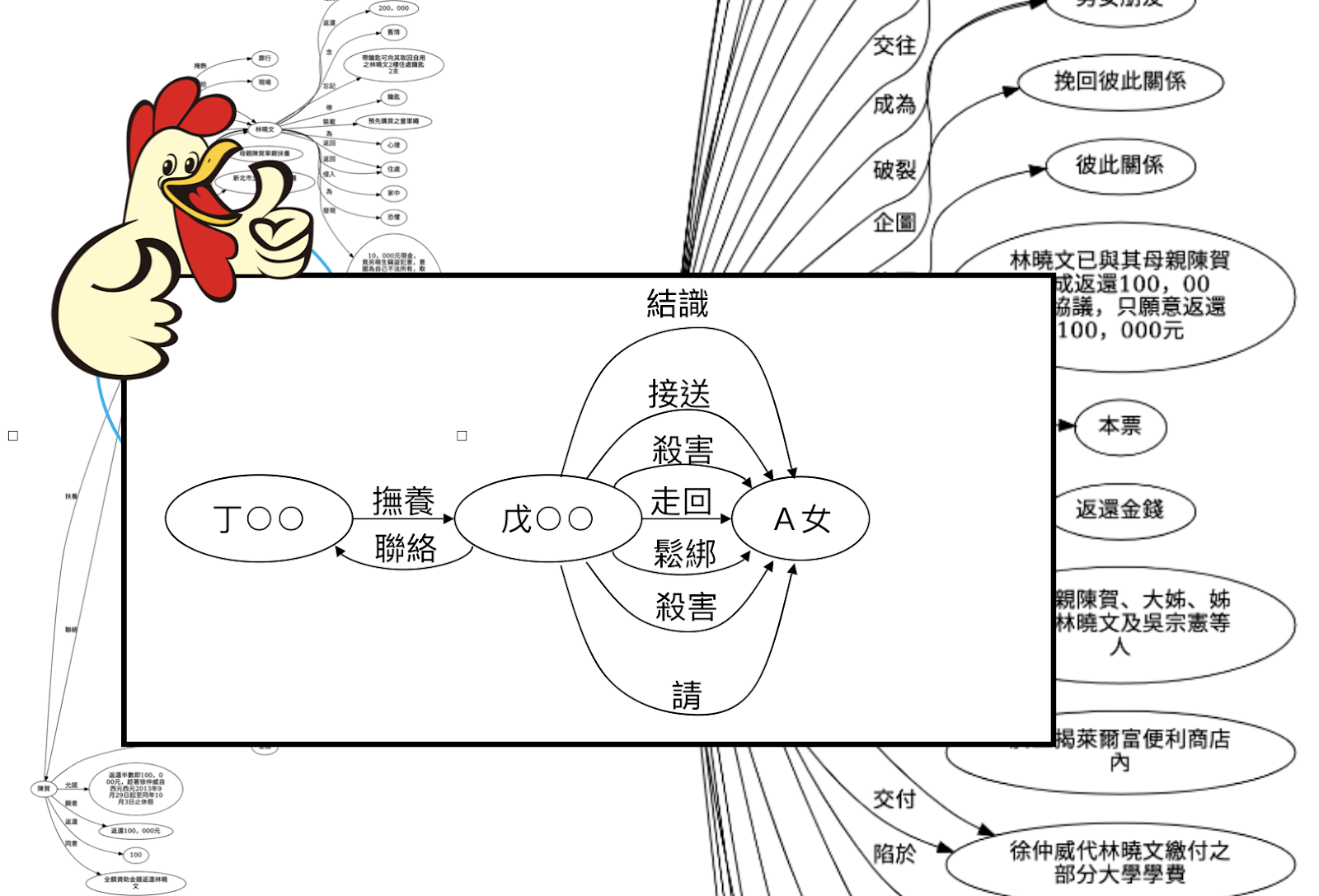
- 自動視覺化
將複雜的法學文件自動轉換成視覺化模式,例如當事人之間的關係或是時間軸等等的模式稱之。
這種應用場景較為冷門,目前僅觀察到「法律科技黑客松:判決視覺化工具,吳采軒等」使用 OpenIE 概念,結構化判決書後將其視覺化表現。
- 產業活動
此類別指的是並非以法律領域的應用為核心,但在法律產業活動上使用到人工智慧的技術。
例如 OCR 和 Speech-to-text 等技術。
OCR(Optical Character Recognition, 光學字元辨識)常用於將紙本文件或掃描文件轉換為文字檔,而Speech-to-text(語音辨識)則可應用於開庭筆錄或會議記錄。
目前司法院正在進行的智慧法庭專案中,就包含將語音識別應用於開庭筆錄,利用人工智慧自動記開庭筆錄,節省書記官的工作量並且提高開庭的效率。而 OCR 也已經導入在電子卷證的流程中。
阻礙與建議
在觀察目前發展現況的同時,Lawsnote 也觀察到一些在執行面遭遇的一些難題,由於目前最廣泛的應用和研究多集中在預測模型,因此大部分的阻礙也發生在預測模型:
- 斷詞
要以人工智慧處理中文,很難不遇到斷詞 (Segment)。斷詞指的是將文本或句子轉換為一個一個的詞 (Term),然而中文複雜的詞性、歧義字和句法結構,使得研究者在斷詞階段面臨很大的挑戰。
目前的斷詞演算法最常見的為中國的開源斷詞演算法 Jeiba 以及 Ansj,中研院開發的 CKIP 由於今年 (2019) 才開源,此前需要取得授權,因此使用率沒有那麼高。另外還有 Standford Chinese Segmenter 以及北京大學的最近的 pkuseg。
上述斷詞演算法要應用於法律資料的處理時,為了優化斷詞結果,必須要輔以法律術語的語料庫,而目前這樣的語料庫內容非常匱乏,因此研究者很容易在斷詞階段就陷入斷詞正確性的困境。
隨著自然語言處理的技術發展,越來越多不同概念的斷詞演算法被提出,例如基於語言學的斷詞系統卓騰斷詞 Articut,在未來可能可以克服更多在斷詞階段面臨的問題。
然而法律名詞和術語的語料庫是斷詞中不可或缺的,因此期待相關語料庫可以逐漸利用社群的力量建置並充實。
- 標註數量級
目前在各種人工智慧建模應用中,大多數專案的建模訓練用的資料量級都非常小,往往在數百到數千筆資料間。
受限於自動標記技術的成熟度,大多專案是透過人工標註,而法律領域專案在這個科目的預算編制往往有限,導致在一般專案中人工能標註的數量級十分有限。
目前法律人工智慧應用尚缺乏標註資料庫共享的概念,期待有單位能主導建立共享的標註資料庫環境,避免在各專案中陷入不斷重複標註,資料量級無法提高的困境。
- 正確性驗證與輸入資訊的侷限
目前研究成果在預測模型的正確性驗證十分困難,原因同上,都是因為缺乏驗證用的測試資料庫,以至於目前的正確率都是研究者自行驗證,並且由於大多專案的不會公開算法和模組,因此也難以再現研究成果。
但相較於學術或司法審判,預測模型在商業應用場景中主要是作為參考性質,因此對於正確率的要求其實不需要達到前兩者般的嚴謹。
然而預測模型在商業應用的困境則是輸入資料的侷限性,舉例而言,一個以詞向量機率模型訓練的預測模型完成後,可以預測任意一篇「裁判」的結果。問題是,裁判書本身已經是帶有判決結果的文本,在現實生活中,去預測一篇已經完成的裁判書結果為何是沒有意義的,民眾需要的是根據(自行描述的)事實去預測裁判結果。
- 成果缺乏可解釋性
目前大多數的預測模型都不具有可解釋性,也就是無法解釋預測結果的成因為何。
這個問題在重視「判決必須敘明理由」的司法審判系統中,是較難以被接受的一環。因為即使一個預測模型的正確率很高,也很難解釋該模型是基於什麼理由,預測出這樣的結果。
- 隱性因子
目前用於預測模型的訓練資料,都是以裁判書內容的記載為主,這些記載可以是詞,可以是因子,也可以是描述。共通點都是這些資訊都是有被記載在裁判書中。
然而司法審判實務上,影響法官作出判決的真實因子,未必會被記載入裁判書中,這是實務上第一線審判者的共識。因此在進行預測模型時,很可能會宥於這些隱性因子產生預測的偏差。
預測偏差加上前面提到的不可解釋性,兩者加在一起的問題成為目前預測模型導入必然面臨,也必須克服的問題。
- 源資料的問題
要將人工智慧導入於法律領域,數據(結構化資料)是不可或缺的。然而目前國內的開放法學資料在取得以及結構化的成本非常高,因此對於研究者產生很大的阻礙。
雖然目前公開裁判書有按月提供資料集下載,讓資料取得成本下降許多,但文本高度非結構化的狀況,導致在研究過程中中多數時間都花在清洗以及結構化資料上。
而公開的法規及函釋等開放資料,由於缺乏集中的資料源,導致光是取得完整資料客觀上都不太可行,這也是目前的人工智慧發展,極少以法規和函釋為訓練素材的原因。
若要推行人工智慧在法律領域的發展,解決源資料的問題絕對是重中之重。
- 人才
人工智慧與法律都是高度專業化的能力,因此要將人工智慧應用於法律,協作團隊必須同時兼具技術能力以及法律專業。
從 2016 年以來人工智慧逐漸受到法律圈的重視,然而在技術社群,卻沒有觀察到有對法律科技應用感到同等興趣。
例如 g0v 的大松,雖然 2013 年開始每年有數個法律領域相關專案,但從 2018 年後幾乎沒有法律相關的專案提案出現,而此前的專案大多也在參與者不多的情況下舉步維艱。
閱讀法律資料對於技術人來說不是件愉悅的事情,因此資料清洗過程伴隨的痛苦感很容易讓專案夭折,相較於法律,許多與社會大眾息息相關的領域更引起技術社群的偏愛。
而法律專業領域者由於養成過程中較缺乏對人工智慧概念性和系統性的認識,縱使有志要利用人工智慧解決法律領域的問題,思維上也較容易以法學方法論的角度切入,而在應用情境的想像力較難突破。
因此在從事人工智慧應用於法律領域,人才的匱乏,難以找到合適的協作對象是目前觀察到的困境。
由於觀察到上述問題,我們也對未來的發展提供一些想法:
- 底層技術的研究
觀察現在人工智慧應用於法律領域的狀況,多數的場景在於產出一個完整、可以獨立運作的成果,例如預測模型,本身即是完整而獨立的服務。
打造預測模型這樣完整的服務,現行狀況在過程中會面臨許多問題,例如上述的斷詞、資料數量級、演算法黑箱等等。而這些問題其實本身就可能單獨構成一個人工智慧應用於法律的題目。
例如透過人工智慧進行裁判書的自動結構化和自動標籤,雖然本身並不是一個完整的服務,只是一個技術節點,一種底層技術,然而這樣的研究將會對未來其他的研究起到非常重要的價值。
在堆疊出準確泛用的預測模組之前,堅實的底層技術研究是非常重要的,目前觀察到,在法律圈利用人工智慧帶來底層技術的突破仍然非常少數,Lawsnote 建議未來的研究者可以在多關注底層技術,例如斷詞機制、自動標記和結構化、可解釋性的人工智慧設計等。
- 強化資料開放與結構化
人工智慧的發展需要大量的結構化資料、方法論的探索和大量的資源投入,在法律領域的人工智慧發展,這三個工作項目最理想的狀況是由官方、學界和產業界分工並進。
法律資料的開放與結構化最適合由官方來進行,因為有許多事是只有官方才能做得到。目前的裁判書雖然有透過資料集的方式公開,然而由於文本的非結構化程度嚴重,要應用於人工智慧仍要克服許多問題。在司法文件的編輯上,聯合國有 Akoma Natoso 的 xml 編輯規範可供參考。
而法規和函釋目前則是在資料開放源就非常破碎且不完整,導致光是要取得就非常困難,要應用於人工智慧更顯困難。
這部分的強化只有官方能完成,而強化資料的開放和結構,絕對是發展人工智慧的首要任務。
- 利用 GitHub 共享資料
在 Lawsnote 的觀察中。目前許多專案都會各自以人工方式建置「斷詞語料庫」以及「標記資料」,然而這些標記好的語料庫或資料往往在專案結束後就不再利用,未來若有研究者要進行進階的研究,仍需要從新建置語料庫和自行標記資料。為了避免重複的標記導致資源的消耗,我們希望透過本篇報告推廣將學術研究的標記資料和語料庫可以上傳至 GitHub,以便未來的研究者進一步的利用。
- 人才養成
將人工智慧應用於法律領域,主要需要兩個角色來完成,一是掌握法律領域知識發現問題的人,二是執行解決方案的人,專案的執行必須由兩者間持續的協調來完成。
在我們過去的經驗中發現,目前法律專業人才在求學或職場上,比較缺乏和不同領域的專業人士協作的經驗,因此跨領域的整合與溝通是較大的挑戰,因此在人才的養成上,若能有更多法律人和其他領域的專業人士協作的機會,對於法律圈的整合能力養成,以及吸引技術圈對法律領域產生興趣都會有所幫助。
—
Lawsnote 為台灣法律科技方案解決公司,使用科技提高法律產業的效率,並致力節省法律人時間。
www.lawsnote.com
[…] Lawsnote 授權轉載,原文在此 Image by mohamed […]
[目前法律人工智慧應用尚缺乏標註資料庫共享的概念,期待有單位能主導建立共享的標註資料庫環境,避免在各專案中陷入不斷重複標註,資料量級無法提高的困境。]
想要詢問: 標註方式為何?
每個團隊的~研究方向, 都不太一樣,
每個團隊的~標註方式, 可能也不太一樣,
標註方式, 有最大公因數嗎?
標註資料庫, 如何共享?
只是對這個問題, 有點興趣吧
研究方式會影響標註方式是真的,以判決預測的建模來說,最常見的方法論是立基於「法實證研究」的方法論,首先會將可能影響判決的因子定義,做成code book,並從data中根據code book的定義抽取資訊。此時標籤會根據code book的類別而定,這是目前最主流的預測模組的標記方法。
而案件類型的研究,以婚姻和交通事件為大宗(同時也是判決數量的大宗)。
資料庫共享機制,以現在判決官方有提供UID(JID)而言,每篇判決如果已經抽取出特定code book的定義,是有可能在類似的研究領域重複使用的。
[…] 前文雖然提到人工智慧和深度學習等概念,但實際上法律科技在人工智慧領域通常專注在自然語言處理以及語意分析,較常使用的模型為利用詞與文本生成的向量模型,例如Word2Vec、Doc2Vec和LSTM等(詳細可參考Lawsnote去年的「人工智慧在台灣法律領域的發展狀況2019觀察報告」)。在一個任務中經常交叉使用許多不同的模型來完成任務,也因此,在這些應用場景中「斷詞」(segment)的準確度會大幅度影響到模型的結果。 […]